Iterative Learning
Try again and get better.
Humans are able to acquire incredible skills by practicing particular tasks over and over again. Our goal is to equip dynamic systems with the ability to learn from past experience and thus perform amazingly agile, adapted and accurate motions.
Humans learn from experience: when we try something and fail, we try doing it a different way the next time around. And we are incredibly efficient at this process. In fact, our ability to learn and adapt is so sophisticated, that when it comes to complex activities such as racing a car or playing a violin, we can easily outperform automated systems. This is why we use autopilot programs for the routine aspects of flying a plane (such as cruising, take-off and landing), but why we still need human pilots to handle unexpected events and emergencies.
Our goal is to develop algorithms that narrow this learning gap between humans and machines, and enable autonomous systems to ‘learn’ the way humans do: through practice.
Rather than being programmed with detailed instructions, our systems will learn from experience. Like baby birds leaving the nest, they will be clumsy at first. Over time, however, they will become capable of sophisticated, coordinated maneuvers.
Unlike humans, these systems won’t make the same mistake twice. And, when networked, they have the added advantage of being able to learn from each other’s successes and failures. The result is an impressively steep learning curve.
Why not allowing autonomous robots to practice before demonstrating their artistic skills? And why aren’t automated systems able to improve their performance when repeatedly executing the same task?
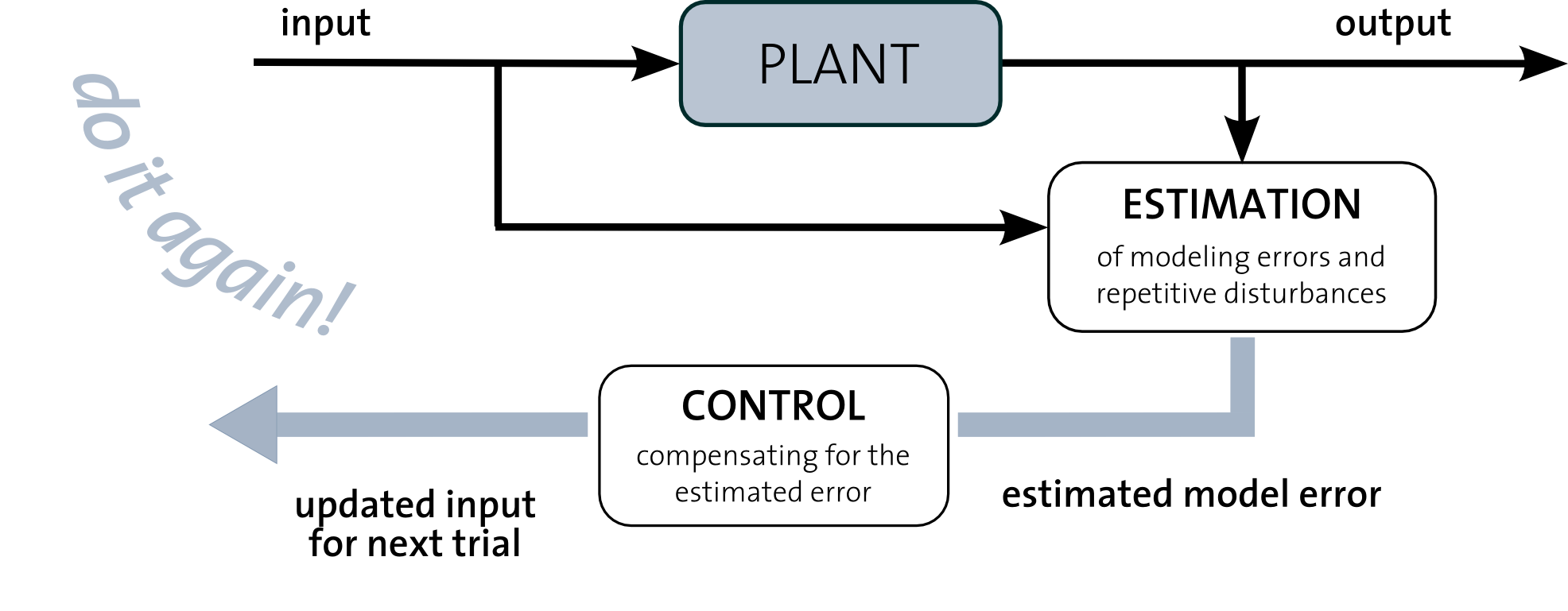
We develop algorithms that enable autonomous systems to learn from their past experience. The information about previous trials is made available to the system and learning rules are designed which exploit the repetitiveness of the execution. Existing knowledge about the system dynamics, e.g. coarse first principle models, are incorporated in these learning rules.
Our initial learning algorithms [1]-[2] fall in the area of iterative learning control. Here, traditional optimal filtering methods are combined with state-of-the-art convex optimization techniques in order to first estimate the error between the desired motion and the actual outcome and then to correct for it. This yields a more appropriate open-loop input that is applied in the next trial. Importantly, the derived formalism allows for the direct treatment of input and state constraints. A first implementation on a cart-pendulum system demonstrated the effectiveness of the learning scheme. More recently, we have applied the learning scheme to quadrocopters.
[1] A.P. Schoellig and R. D'Andrea, Learning through Experience - Optimizing Performance by Repetition, Poster at IEEE/RSJ 2008 International Conference on Intelligent Robots and Systems, 2008.
DownloadDownload (PDF, 14.4 MB)
[2] A.P. Schoellig and R. D'Andrea, Optimization-Based Iterative Learning Control for Trajectory Tracking, European Control Conference, 2009, page 1505-1510.
DownloadDownload (PDF, 367 KB)
Having successfully implemented a learning stratgegy for one dynamic system, the question arose: If having multiple similar agents - imagine a fleet of robots - is it possible to benefit from exchanging information during the learning process? Recently, some first theoretic results considering this multi-agent problem were derived [3]-[5].
[3] A.P. Schoellig, J. Alonso-Mora and R. D'Andrea, Independent vs. Joint Estimation in Multi-Agent Iterative Learning Control, IEEE Conference on Decision and Control, 2010, pages 6949-6954.
DownloadDownload (PDF, 482 KB)
[4] A.P. Schoellig, J. Alonso-Mora and R. D'Andrea, Limited Benefit of Joint Estimation in Multi-Agent Iterative Learning Control, Asian Journal of Control - Special Issue on Iterative Learning Control, 2010, pages 613–623
external pageDownload
[5] A.P. Schoellig and R. D'Andrea, Sensitivity of Joint Estimation in Multi-Agent Iterative Learning Control, IFAC World Congress, 2011, submitted.
DownloadDownload (PDF)
Can you imagine a quadrocopter that does multiple flips in the air? Sergei Lupashin implemented a policy gradient method [5] that gradually improves the flip motion by combining iterative experiments with information from a first-principles model. With this problem-specific learning method, the quadrocopter is able to perform a triple flip with a turn rate of 1600 degrees per second. Around 40 iterations are necessary to learn this motion and accurately finish the maneuver, where it started. See a external pagedemonstration in our Flying Machine Arena.
This is a maneuver which would never be possible by flying the vehicle manually nor by using standard feedback control.
[5] S. Lupashin, A.P. Schoellig, M. Sherback and R. D’Andrea, A Simple Learning Strategy for High-Speed Quadrocopter Multi-Flips, IEEE International Conference on Robotics and Automation, 2010, page 1642-1648.
DownloadDownload (PDF, 1.1 MB)
Below is a list of past projects and participants:
Studies on Mechatronics
- Robert Stettler, Interaction and Information Sharing between Multiple Systems - A Categorization and Evaluation, 2010.
Bachelor Thesis
- Fabian Müller, An Automated Testing Platform for Learning Algorithms, 2009.
Semester Project
- Sonja Stüdli, Fly! Iterative Learning for Quadrocopters, 2009.
- Javier Alonso-Mora, Extending Iterative Learning Control to Multi-Agent Systems, 2009.
